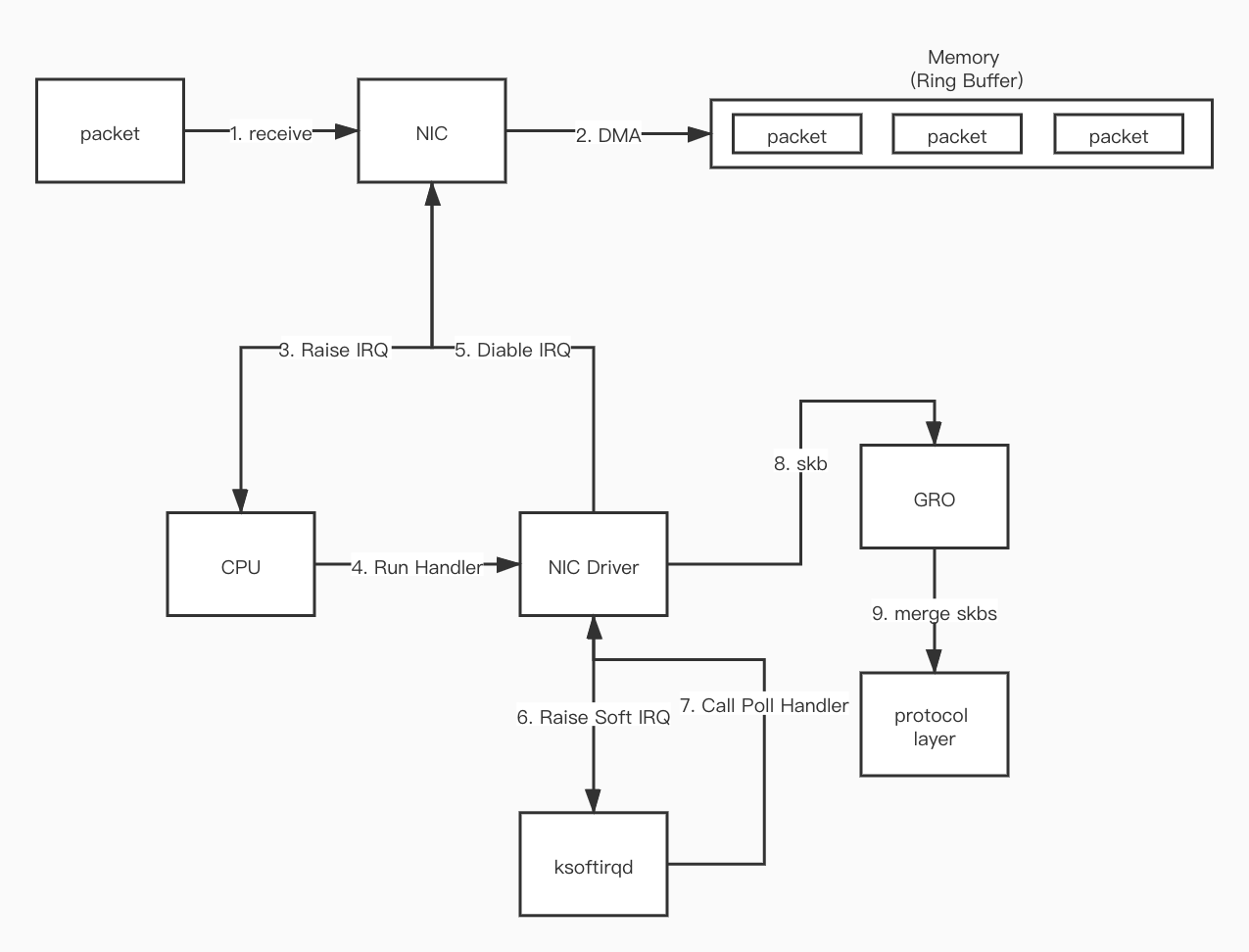
本篇文章主要围绕两种 DNS Server 的实现方式展开,会比较两种 Server 的优缺点。在说两个 Service 之前,我们先来了解一下在k8s中域名是如何被解析的。
我们都知道,在 k8s 中,一个 Pod 如果要访问同 Namespace 下的 Service(比如 user-svc),那么只需要curl user-svc。如果 Pod 和 Service 不在同一域名下,那么就需要在 Service Name 之后添加上 Service 所在的 Namespace(比如 beta),curl user-svc.beta。那么 k8s 是如何知道这些域名是内部域名并为他们做解析的呢?
DNS In Kubernetes
/etc/resolv.conf
resolv.conf 是 DNS 域名解析的配置文件。每行都会以一个关键字开头,然后跟配置参数。这里主要使用到的关键词有3个。
- nameserver #定义 DNS 服务器的 IP 地址
- search #定义域名的搜索列表,当查询的域名中包含的
. 的数量少于 options.ndots 的值时,会依次匹配列表中的每个值 - options #定义域名查找时的配置信息
那么我们进入一个 Pod 查看它的 resolv.conf
nameserver 100.64.0.10search default.svc.cluster.local svc.cluster.local cluster.localoptions ndots:5
这里的 nameserver、search 和 options 都是可以通过 dnsConfig 字段进行配置的,官方文档中已有详细的讲述
上述配置文件 resolv.conf 是 dnsPolicy: ClusterFirst 情况下,k8s 为 Pod 自动生成的,这里的 nameserver 所对应的地址正是 DNS Service 的Cluster IP(该值在启动 kubelet 的时候,通过 clusterDNS 指定)。所以,从集群内请求的所有的域名解析都需要经过 DNS Service 进行解析,不管是 k8s 内部域名还是外部域名。
可以看到这里的 search 域默认包含了 namespace.svc.cluster.local、svc.cluster.local 和 cluster.local 三种。当我们在 Pod 中访问 a Service时( curl a ),会选择nameserver 100.64.0.10 进行解析,然后依次带入 search 域进行 DNS 查找,直到找到为止。
# curl aa.default.svc.cluster.local
显然因为 Pod 和 a Service 在同一 Namespace 下,所以第一次 lookup 就能找到。
如果 Pod 要访问不同 Namespace(例如: beta )下的 Service b ( curl b.beta ),会经过两次 DNS 查找,分别是
# curl b.betab.beta.default.svc.cluster.local(未找到)b.beta.svc.cluster.local(找到)
正是因为 search 的顺序性,所以访问同一 Namespace 下的 Service, curl a 是要比 curl a.default 的效率更高的,因为后者多经过了一次 DNS 解析。
# curl aa.default.svc.cluster.local# curl a.defaultb.default.default.svc.cluster.local(未找到)b.default.svc.cluster.local(找到)
那么当Pod中访问外部域名时仍然需要走search域吗?
这个答案,不能说肯定也不能说否定,看情况,可以说,大部分情况要走 search 域。
以 domgoer.com 为例,通过抓包的方式,在某一个Pod中访问 domgoer.com ,可以看到 DNS 查找的过程,都产生了什么样的数据包。首先先进入 DNS 容器的网络。
ps: 由于 DNS 容器往往不具备 bash,所以不能通过 docker exec 的方式进入容器抓包,需要采用其他方法
// 1.找到容器ID,打印它的NS IDdocker inspect --format "{{.State.Pid}}" container_id// 2.进入此容器的Namespacensenter -n -t pid// 3.DNS抓包tcpdump -i eth0 -N udp dst port 53
在其他容器中进行domgoer.com域名查找
nslookup domgoer.com dns_container_ip
指定 dns_container_ip,是为了避免有多个DNS容器的情况,DNS请求会分到各个容器。这样可以让 DNS 请求只发往这个地址,这样抓包的数据才会完整。
可以看到如下的结果:
17:01:28.732260 IP 172.20.92.100.36326 > nodexxxx.domain: 4394+ A? domgoer.com.default.svc.cluster.local. (50)17:01:28.733158 IP 172.20.92.100.49846 > nodexxxx.domain: 60286+ A? domgoer.com.svc.cluster.local. (45)17:01:28.733888 IP 172.20.92.100.51933 > nodexxxx.domain: 63077+ A? domgoer.com.cluster.local. (41)17:01:28.734588 IP 172.20.92.100.33401 > nodexxxx.domain: 27896+ A? domgoer.com. (27)17:01:28.734758 IP nodexxxx.34138 > 192.168.x.x.domain: 27896+ A? domgoer.com. (27)
可以看到在真正解析 domgoer.com 之前,经历了 domgoer.com.default.svc.cluster.local. -> domgoer.com.svc.cluster.local. -> domgoer.com.cluster.local. -> domgoer.com.
这样也就意味着有3次DNS请求是浪费的,没有意义的。
如何避免这样的情况
在研究如何避免之前可以下思考一下造成这种情况的原因。在 /etc/resolv.conf 文件中,我们可以看到 options 中有个配置项 ndots:5 。
ndots:5,表示:如果需要 lookup 的 Domain 中包含少于5个 . ,那么将使用非绝对域名,如果需要查询的 DNS 中包含大于或等于5个 . ,那么就会使用绝对域名。如果是绝对域名则不会走 search 域,如果是非绝对域名,就会按照 search 域中进行逐一匹配查询,如果 search 走完了都没有找到,那么就会使用 原域名.(domgoer.com.) 的方式作为绝对域名进行查找。
综上可以找到两种优化的方法
直接使用绝对域名
这是最简单直接的优化方式,可以直接在要访问的域名后面加上 . 如:domgoer.com. ,这样就会避免走 search 域进行匹配。
配置ndots
还记得之前说过 /etc/resolv.conf 中的参数都可以通过k8s中的 dnsConfig 字段进行配置。这就允许你根据你自己的需求配置域名解析的规则。
例如 当域名中包含两个 . 或以上时,就能使用绝对域名直接进行域名解析。
apiVersion: v1kind: Podmetadata:namespace: defaultname: dns-examplespec:containers:- name: test image: nginxdnsConfig: options: - name: ndots value: 2
Kubernetes DNS 策略
在k8s中,有4中DNS策略,分别是 ClusterFirstWithHostNet 、ClusterFirst 、Default 、和 None,这些策略可以通过 dnsPolicy 这个字段来定义
如果在初始化 Pod、Deployment 或者 RC 等资源时没有定义,则会默认使用 ClusterFirst 策略
ClusterFirstWithHostNet
当一个 Pod 以 HOST 模式(和宿主机共享网络)启动时,这个 POD 中的所有容器都会使用宿主机的/etc/resolv.conf 配置进行 DNS 查询,但是如果你还想继续使用 Kubernetes 的 DNS 服务,
就需要将 dnsPolicy 设置为 ClusterFirstWithHostNet。
ClusterFirst
使用这是方式表示 Pod 内的 DNS 优先会使用 k8s 集群内的DNS服务,也就是会使用 kubedns 或者 coredns 进行域名解析。如果解析不成功,才会使用宿主机的 DNS 配置进行解析。
Default
这种方式,会让 kubelet 来绝定 Pod 内的 DNS 使用哪种 DNS 策略。kubelet 的默认方式,其实就是使用宿主机的 /etc/resolv.conf 来进行解析。你可以通过设置 kubelet 的启动参数,
–resolv-conf=/etc/resolv.conf 来决定 DNS 解析文件的地址
None
这种方式顾名思义,不会使用集群和宿主机的 DNS 策略。而是和 dnsConfig 配合一起使用,来自定义 DNS 配置,否则在提交修改时报错。
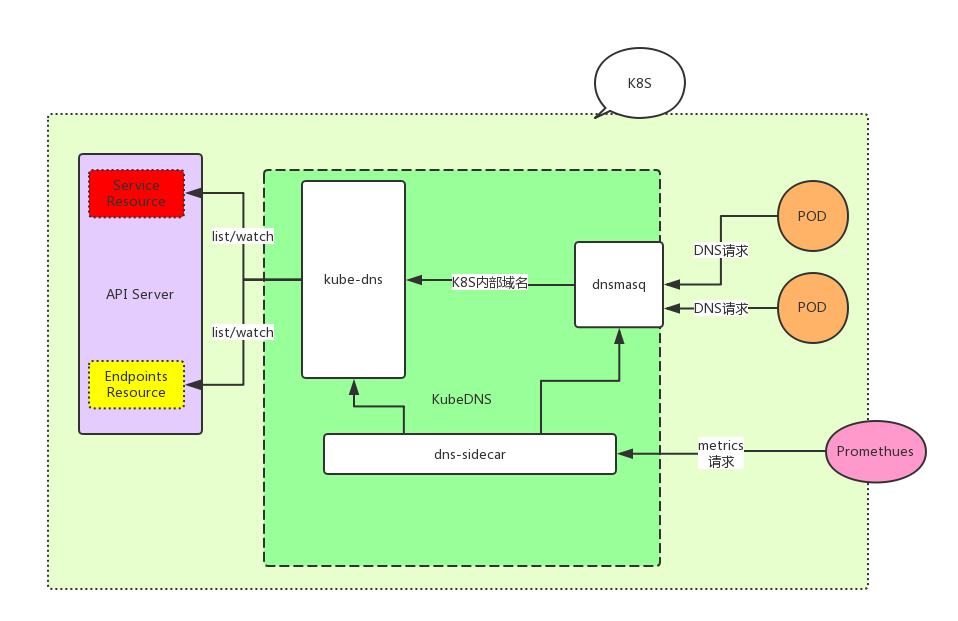
结构
kubeDNS由3个部分组成。
- kubedns: 依赖
client-go 中的 informer 机制监视 k8s 中的 Service 和 Endpoint 的变化,并将这些结构维护进内存来服务内部 DNS 解析请求。 - dnsmasq: 区分 Domain 是集群内部还是外部,给外部域名提供上游解析,内部域名发往 10053 端口,并将解析结果缓存,提高解析效率。
- sidecar: 对 kubedns 和 dnsmasq 进行健康检查和收集监控指标。
以下是结构图
![]()
kubedns
在 kubedns 包含两个部分, kubedns 和 skydns。
其中 kubedns 是负责监听 k8s 集群中的 Service 和 Endpoint 的变化,并将这些变化通过 treecache 的数据结构缓存下来,作为 Backend 给 skydns 提供 Record。
而真正负责dns解析的其实是 skydns(skydns 目前有两个版本 skydns1 和 skydns2,下面所说的是 skydns2,也是当前 kubedns 所使用的版本)。
我们可以先看下 treecache,以下是 treecache 的数据结构
// /dns/pkg/dns/treecache/treecache.go#54type treeCache struct { ChildNodes map[string]*treeCache Entries map[string]interface{}}
我们再看一组实际的数据
{ "ChildNodes": { "local": { "ChildNodes": { "cluster": { "ChildNodes": { "svc": { "ChildNodes": { "namespace": { "ChildNodes": { "service_name": { "ChildNodes": { "_tcp": { "ChildNodes": { "_http": { "ChildNodes": {}, "Entries": { "6566333238383366": { "host": "service.namespace.svc.cluster.local.", "port": 80, "priority": 10, "weight": 10, "ttl": 30 } }, } }, "Entries": {} } }, "Entries": { "3864303934303632": { "host": "100.70.28.188", "priority": 10, "weight": 10, "ttl": 30 } } } }, "Entries": {} } }, "Entries": {} } }, "Entries": {} } }, "Entries": {} } }, "Entries": {}}
treeCache 的结构类似于目录树。从根节点到叶子节点的每个路径与一个域名是相对应的,顺序是颠倒的。它的叶子节点只包含 Entries,非叶子节点只包含 ChildNodes。叶子节点中保存的就是 SkyDNS 定义的 msg.Service 结构,可以理解为 DNS 记录。
在 Records 接口方法实现中,只需根据域名查找到对应的叶子节点,并返回叶子节点中保存的所有msg.Service 数据。K8S 就是通过这样的一个数据结构来保存 DNS 记录的,并替换了 Etcd( skydns2 默认使用 etcd 作为存储),来提供基于内存的高效存储。
我们可以直接阅读代码来了解 kubedns 的启动流程。
首先看它的结构体
// dns/cmd/kube-dns/app/server.go#43type KubeDNSServer struct { // DNS domain name. = cluster.local. domain string healthzPort int // skydns启动的地址和端口 dnsBindAddress string dnsPort int nameServers string kd *dns.KubeDNS}
下来可以看到一个叫 NewKubeDNSServerDefault 的函数,它初始化了 KubeDNSServer。并执行 server.Run() 启动了服务。那么我们来看下 NewKubeDNSServerDefault 这个方法做了什么。
// dns/cmd/kube-dns/app/server.go#53func NewKubeDNSServerDefault(config *options.KubeDNSConfig) *KubeDNSServer { kubeClient, err := newKubeClient(config) if err != nil { glog.Fatalf("Failed to create a kubernetes client: %v", err) } // 同步配置文件,如果观察到配置信息改变,就会重启skydns var configSync dnsconfig.Sync switch { // 同时配置了 configMap 和 configDir 会报错 case config.ConfigMap != "" && config.ConfigDir != "": glog.Fatal("Cannot use both ConfigMap and ConfigDir") case config.ConfigMap != "": configSync = dnsconfig.NewConfigMapSync(kubeClient, config.ConfigMapNs, config.ConfigMap) case config.ConfigDir != "": configSync = dnsconfig.NewFileSync(config.ConfigDir, config.ConfigPeriod) default: conf := dnsconfig.Config{Federations: config.Federations} if len(config.NameServers) > 0 { conf.UpstreamNameservers = strings.Split(config.NameServers, ",") } configSync = dnsconfig.NewNopSync(&conf) } return &KubeDNSServer{ domain: config.ClusterDomain, healthzPort: config.HealthzPort, dnsBindAddress: config.DNSBindAddress, dnsPort: config.DNSPort, nameServers: config.NameServers, kd: dns.NewKubeDNS(kubeClient, config.ClusterDomain, config.InitialSyncTimeout, configSync), }}// 启动skydns serverfunc (d *KubeDNSServer) startSkyDNSServer() { skydnsConfig := &server.Config{ Domain: d.domain, DnsAddr: fmt.Sprintf("%s:%d", d.dnsBindAddress, d.dnsPort), } if err := server.SetDefaults(skydnsConfig); err != nil { glog.Fatalf("Failed to set defaults for Skydns server: %s", err) } // 使用d.kd作为存储的后端,因为kubedns实现了skydns.Backend的接口 s := server.New(d.kd, skydnsConfig) if err := metrics.Metrics(); err != nil { glog.Fatalf("Skydns metrics error: %s", err) } else if metrics.Port != "" { glog.V(0).Infof("Skydns metrics enabled (%v:%v)", metrics.Path, metrics.Port) } else { glog.V(0).Infof("Skydns metrics not enabled") } d.kd.SkyDNSConfig = skydnsConfig go s.Run()}
可以看到这里 dnsconfig 会返回一个 configSync 的 interface 用来实时同步配置,也就是 kube-dns 这个 configmap,或者是本地的 dir(但一般来说这个 dir 也是由 configmap 挂载进去的)。在方法的最后 dns.NewKubeDNS 返回一个 KubeDNS 的结构体。那么我们看下这个函数初始化了哪些东西。
// dns/pkg/dnsdns.go#124func NewKubeDNS(client clientset.Interface, clusterDomain string, timeout time.Duration, configSync config.Sync) *KubeDNS { kd := &KubeDNS{ kubeClient: client, domain: clusterDomain, cache: treecache.NewTreeCache(), cacheLock: sync.RWMutex{}, nodesStore: kcache.NewStore(kcache.MetaNamespaceKeyFunc), reverseRecordMap: make(map[string]*skymsg.Service), clusterIPServiceMap: make(map[string]*v1.Service), domainPath: util.ReverseArray(strings.Split(strings.TrimRight(clusterDomain, "."), ".")), initialSyncTimeout: timeout, configLock: sync.RWMutex{}, configSync: configSync, } kd.setEndpointsStore() kd.setServicesStore() return kd}
可以看到kd.setEndpointsStore() 和 kd.setServicesStore() 这两个方法会在 informer中注册 Service 和 Endpoint 的回调,用来观测这些资源的变动并作出相应的调整。
下面我们看下当集群中新增一个 Service,kubedns 会以怎样的方式处理。
// dns/pkg/dns/dns.go#499func (kd *KubeDNS) newPortalService(service *v1.Service) { // 构建了一个空的叶子节点, recordLabel是clusterIP经过 FNV-1a hash运算后得到的32位数字 // recordValue 的结构 // &msg.Service{ // Host: service.Spec.ClusterIP, // Port: 0, // Priority: defaultPriority, // Weight: defaultWeight, // Ttl: defaultTTL, // } subCache := treecache.NewTreeCache() recordValue, recordLabel := util.GetSkyMsg(service.Spec.ClusterIP, 0) subCache.SetEntry(recordLabel, recordValue, kd.fqdn(service, recordLabel)) // 查看service的ports列表,将每个port信息转换成skydns.Service并加入上面构建的叶子节点 for i := range service.Spec.Ports { port := &service.Spec.Ports[i] if port.Name != "" && port.Protocol != "" { srvValue := kd.generateSRVRecordValue(service, int(port.Port)) l := []string{"_" + strings.ToLower(string(port.Protocol)), "_" + port.Name} subCache.SetEntry(recordLabel, srvValue, kd.fqdn(service, append(l, recordLabel)...), l...) } } subCachePath := append(kd.domainPath, serviceSubdomain, service.Namespace) host := getServiceFQDN(kd.domain, service) reverseRecord, _ := util.GetSkyMsg(host, 0) kd.cacheLock.Lock() defer kd.cacheLock.Unlock() // 将构建好的叶子节点加入treecache kd.cache.SetSubCache(service.Name, subCache, subCachePath...) kd.reverseRecordMap[service.Spec.ClusterIP] = reverseRecord kd.clusterIPServiceMap[service.Spec.ClusterIP] = service}
再看一下当 Endpoint 添加到集群时,kubedns 会如何处理
// dns/pkg/dns/dns.go#460func (kd *KubeDNS) addDNSUsingEndpoints(e *v1.Endpoints) error { // 获取ep所属的svc svc, err := kd.getServiceFromEndpoints(e) if err != nil { return err } // 判断这个svc,如果这个svc不是 headless,就不会处理此次添加,因为 svc 有 clusterIP 的情况,在处理 // svc 的增删改时已经都被处理了。所以当 ep 属于 headless svc 时,需要将这个 ep 加入到 cache if svc == nil || v1.IsServiceIPSet(svc) || svc.Spec.Type == v1.ServiceTypeExternalName { // No headless service found corresponding to endpoints object. return nil } return kd.generateRecordsForHeadlessService(e, svc)}// 把 endpoint 添加到它所属的 headless service 的缓存下func (kd *KubeDNS) generateRecordsForHeadlessService(e *v1.Endpoints, svc *v1.Service) error { subCache := treecache.NewTreeCache() generatedRecords := map[string]*skymsg.Service{} // 遍历这个 ep 下所有的 ip+port,并将它们添加到 treecache 中 for idx := range e.Subsets { for subIdx := range e.Subsets[idx].Addresses { address := &e.Subsets[idx].Addresses[subIdx] endpointIP := address.IP recordValue, endpointName := util.GetSkyMsg(endpointIP, 0) if hostLabel, exists := getHostname(address); exists { endpointName = hostLabel } subCache.SetEntry(endpointName, recordValue, kd.fqdn(svc, endpointName)) for portIdx := range e.Subsets[idx].Ports { endpointPort := &e.Subsets[idx].Ports[portIdx] if endpointPort.Name != "" && endpointPort.Protocol != "" { srvValue := kd.generateSRVRecordValue(svc, int(endpointPort.Port), endpointName) l := []string{"_" + strings.ToLower(string(endpointPort.Protocol)), "_" + endpointPort.Name} subCache.SetEntry(endpointName, srvValue, kd.fqdn(svc, append(l, endpointName)...), l...) } } // Generate PTR records only for Named Headless service. if _, has := getHostname(address); has { reverseRecord, _ := util.GetSkyMsg(kd.fqdn(svc, endpointName), 0) generatedRecords[endpointIP] = reverseRecord } } } subCachePath := append(kd.domainPath, serviceSubdomain, svc.Namespace) kd.cacheLock.Lock() defer kd.cacheLock.Unlock() for endpointIP, reverseRecord := range generatedRecords { kd.reverseRecordMap[endpointIP] = reverseRecord } kd.cache.SetSubCache(svc.Name, subCache, subCachePath...) return nil}
整体流程其实和 Service 差不多,只不过在添加 cache 之前会先去查找Endpoint所属的 Service,然后不同的是 Endpoint 的叶子节点中的host存储的是 EndpointIP,而 Service 的叶子节点的 host 中存储的是 fqdn。
kubedns总结
kubedns 有两个模块,kubedns和skydns,kubedns负责监听Service和Endpoint并将它们转换为 skydns 能够理解的格式,以目录树的形式存在内存中。
因为 skydns 是以 etcd 的标准作为后端存储的,所以为了兼容 etcd ,kubedns 在错误信息方面都以 etcd 的格式进行定义的。因此 kubedns 的作用其实可以理解为为 skydns 提供存储。
dnsmasq
dnsmasq 由两个部分组成
1.dnsmasq-nanny,容器里的1号进程,不负责处理 DNS LookUp 请求,只负责管理 dnsmasq。
2.dnsmasq,负责处理 DNS LookUp 请求,并缓存结果。
dnsmasq-nanny 负责监控 config 文件(/etc/k8s/dns/dnsmasq-nanny,也就是kube-dns-config这个 configmap 所挂载的位置)的变化(每 10s 查看一次),如果 config 变化了就会Kill掉 dnsmasq,并重新启动它。
// dns/pkg/dnsmasq/nanny.go#198// RunNanny 启动 nanny 服务并处理配置变化func RunNanny(sync config.Sync, opts RunNannyOpts, kubednsServer string) { // ... configChan := sync.Periodic() for { select { // ... // 观察到config变化 case currentConfig = <-configChan: if opts.RestartOnChange { // 直接杀掉dnsmasq进程 nanny.Kill() nanny = &Nanny{Exec: opts.DnsmasqExec} // 重新加载配置 nanny.Configure(opts.DnsmasqArgs, currentConfig, kubednsServer) // 重新启动dnsmasq进程 nanny.Start() } else { glog.V(2).Infof("Not restarting dnsmasq (--restartDnsmasq=false)") } break } }}
让我们看下 sync.Periodic() 这个函数做了些什么
// dns/pkg/dns/config/sync.go#81func (sync *kubeSync) Periodic() <-chan *Config { go func() { // Periodic函数中设置了一个Tick,每10s会去load一下configDir下 // 所有的文件,并对每个文件进行sha256的摘要计算 // 并将这个结果返回。 resultChan := sync.syncSource.Periodic() for { syncResult := <-resultChan // processUpdate函数会比较新的文件的版本和旧的 // 文件的版本,如果不一致会返回changed。 // 值得注意的是有三个文件是需要单独处理的 // federations // stubDomains // upstreamNameservers // 当这三个文件变化是会触发单独的函数(打印日志) config, changed, err := sync.processUpdate(syncResult, false) if err != nil { continue } if !changed { continue } sync.channel <- config } }() return sync.channel}
dnsmasq 中是如何加载配置的呢?
// dns/pkg/dnsmasq/nanny.go#58// Configure the nanny. This must be called before Start().// 这个函数会配置 dnsmasq,Nanny 每次 Kill 掉 dnsmasq 后,调用 Start() 之前都会调用这个函数// 重新加载配置。func (n *Nanny) Configure(args []string, config *config.Config, kubednsServer string) { // ... for domain, serverList := range config.StubDomains { resolver := &net.Resolver{ PreferGo: true, Dial: func(ctx context.Context, network, address string) (net.Conn, error) { d := net.Dialer{} return d.DialContext(ctx, "udp", kubednsServer) }, } // 因为 stubDomain 中可以是以 host:port 的形式存在,所以这里还要做一次 上游的 dns 解析 for _, server := range serverList { if isIP := (net.ParseIP(server) != nil); !isIP { switch { // 如果 server 是以 cluster.local(不知道为什么这里是 hardCode 的)结尾的,就会发往 kubednsServer 进行 DNS 解析 // 因为上面已经配置了 d.DialContext(ctx, "udp", kubednsServer) case strings.HasSuffix(server, "cluster.local"): // ... resolver.LookupIPAddr(context.Background(), server) default: // 如果没有以 cluster.local 结尾,就会走外部解析 DNS // ... net.LookupIP(server) } } } } // ...}
sidecar
sidecar 启动后会在内部开启一个协程,并在循环中每默认 5s 向 kubedns 发送一次 dns 解析。并记录解析结果。
sidecar 提供了两个http的接口 /healthcheck/kubedns 和 /healthcheck/dnsmasq 给 k8s 用作 livenessProbe 的健康检查。每次请求,sidecar 会将上述记录的 DNS 解析结果返回。
kubedns的优缺点
优点
- 各个模块都做了很好的解耦,方便开发者上手。
- 依赖 dnsmasq ,性能有保障
缺点
因为 dnsmasq-nanny 重启 dnsmasq 的方式,先杀后起,方式比较粗暴,有可能导致这段时间内大量的 DNS 请求失败。
dnsmasq-nanny 检测文件的方式,可能会导致以下问题:
dnsmasq-nanny 每次遍历目录下的所有文件,然后用 ioutil.ReadFile 读取文件内容。如果目录下文件数量过多,可能出现在遍历的同时文件也在被修改,遍历的速度跟不上修改的速度。
这样可能导致遍历完了,某个配置文件才更新完。那么此时,你读取的一部分文件数据并不是和当前目录下文件数据完全一致,本次会重启 dnsmasq。进而,下次检测,还认为有文件变化,到时候,又重启一次 dnsmasq。这种方式不优雅,但问题不大。
文件的检测,直接使用 ioutil.ReadFile 读取文件内容,也存在问题。如果文件变化,和文件读取同时发生,很可能你读取完,文件的更新都没完成,那么你读取的并非一个完整的文件,而是坏的文件,这种文件,dnsmasq-nanny 无法做解析,不过官方代码中有数据校验,解析失败也问题不大,大不了下个周期的时候,再取到完整数据,再解析一次。
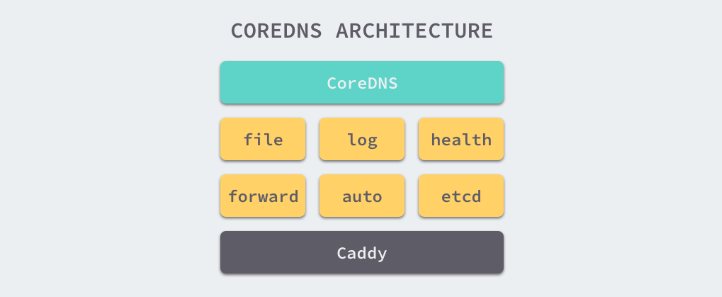
CoreDNS 是一个高速并且十分灵活的DNS服务。CoreDNS 允许你通过编写插件的形式去自行处理DNS数据。
结构图
![]()
CoreDNS 使用Caddy作为底层的 Web Server,Caddy 是一个轻量、易用的Web Server,它支持 HTTP、HTTPS、HTTP/2、GRPC 等多种连接方式。所有 coreDNS 可以通过四种方式对外直接提供 DNS 服务,分别是 UDP、gRPC、HTTPS 和 TLS
CoreDNS 的大多数功能都是由插件来实现的,插件和服务本身都使用了 Caddy 提供的一些功能,所以项目本身也不是特别的复杂。
插件
CoreDNS 定义了一套插件的接口,只要实现 Handler 接口就能将插件注册到插件链中。
type ( // 只需要为插件实现 ServeDNS 以及 Name 这两个接口并且写一些用于配置的代码就可以将插件集成到 CoreDNS 中 Handler interface { ServeDNS(context.Context, dns.ResponseWriter, *dns.Msg) (int, error) Name() string })
现在在 CoreDNS 中已经支持40种左右的插件。
kubernetes
该插件可以让 coreDNS 读取到k8s集群内的 endpoint 以及 service 等信息,从而替代 kubeDNS 作为 k8s 集群内的 DNS 解析服务。不仅如此,该插件还支持多种配置如:
kubernetes [ZONES...] { ; 使用该配置可以连接到远程的k8s集群 kubeconfig KUBECONFIG CONTEXT endpoint URL tls CERT KEY CACERT ; 可以设置需要暴露Service的namespace列表 namespaces NAMESPACE... ; 可以暴露带有特定label的namespace labels EXPRESSION ; 是否可以解析10-0-0-1.ns.pod.cluster.local这种domain(为了兼容kube-dns) pods POD-MODE endpoint_pod_names ttl TTL noendpoints transfer to ADDRESS... fallthrough [ZONES...] ignore empty_service}
forward
提供上游解析功能
forward FROM TO... { except IGNORED_NAMES... ; 强制使用tcp进行域名解析 force_tcp ; 当请求是tcp时,先尝试一次udp解析,失败了再使用tcp prefer_udp expire DURATION ; upstream的healthcheck失败的最多次数,默认2,超过的话upstream就会被下掉 max_fails INTEGER tls CERT KEY CA tls_servername NAME ; 选择nameserver的策略,random、round_robin、sequential policy random|round_robin|sequential health_check DURATION}
更多的插件可以到 CoreDNS 的插件市场查看
Corefile
CoreDNS 提供了一种简单易懂的 DSL 语言,它允许你通过 Corefile 来自定义 DNS 服务。
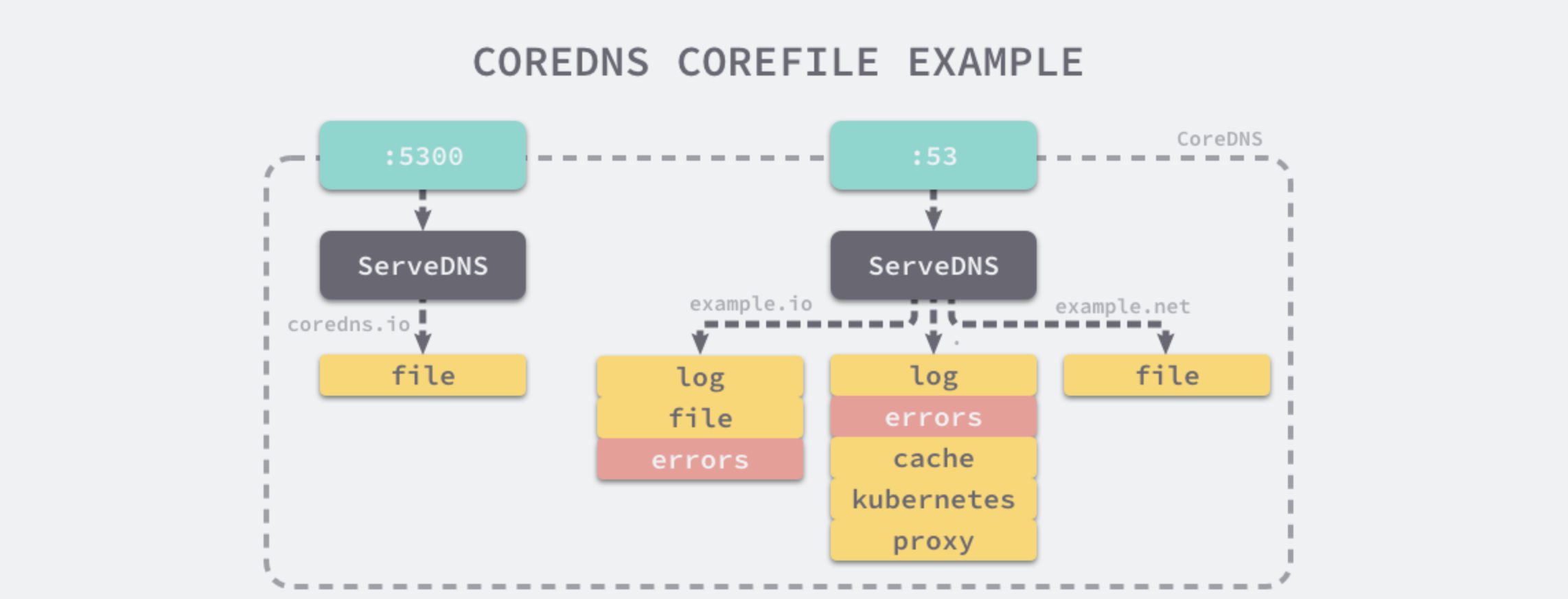
coredns.io:5300 { file db.coredns.io}example.io:53 { log errors file db.example.io}example.net:53 { file db.example.net}.:53 { kubernetes proxy . 8.8.8.8 log errors cache}
通过以上的配置,CoreDNS 会开启两个端口 5300 和 53 ,提供 DNS 解析服务。对于 coredns.io 相关的域名会通过 5300 端口进行解析,其他域名会被解析到 53 端口,不同的域名会应用不同的插件。
![]()
插件原理
在 CoreDNS 中 Plugin 其实就是一个出入参数都是 Handler 的函数
// 所谓的插件链其实是一个Middle layer,通过传递链中的下一个Handler,将一个Handler链接到下一个Handler。type Plugin func(Handler) Handler
同时 CoreDNS 提供了 NextOrFailure 方法,供每个插件在执行完自身的逻辑之后执行下一个插件
// NextOrFailure calls next.ServeDNS when next is not nil, otherwise it will return, a ServerFailure and a nil error.func NextOrFailure(name string, next Handler, ctx context.Context, w dns.ResponseWriter, r *dns.Msg) (int, error) { // nolint: golint if next != nil { if span := ot.SpanFromContext(ctx); span != nil { child := span.Tracer().StartSpan(next.Name(), ot.ChildOf(span.Context())) defer child.Finish() ctx = ot.ContextWithSpan(ctx, child) } return next.ServeDNS(ctx, w, r) } return dns.RcodeServerFailure, Error(name, errors.New("no next plugin found"))}
如果 next 为 nil,说明插件链已经调用结束,直接返回 no next plugin found 的 error 即可。
每个 Plugin 也可以调用 (dns.ResponseWriter).WriteMsg(*dns.Msg) 方法来结束整个调用链。
kubernetes 插件做了什么
CoreDNS 正是通过 kubernetes 插件实现了解析 k8s 集群内域名的功能。那么我们看下这个插件做了些什么事情。
// coredns/plugin/kubernetes/setup.go#44func setup(c *caddy.Controller) error { // 检查了 corefile 中 kubernetes 配置的定义,并配置了一些缺省值 k, err := kubernetesParse(c) if err != nil { return plugin.Error("kubernetes", err) } // 启动了对 pod, service, endpoint 三种资源增、删、改的 watch,并注册了一些回调 // 注意:pod 是否启动 watch 是根据配置文件中 pod 的值来决定的,如果值不是 verified 就不会启动 pod 的 watch // 这里的 watch 方法观测到变化后,仅仅只改变 dns.modified 这个值,它会将该值设置为当前时间戳 err = k.InitKubeCache() if err != nil { return plugin.Error("kubernetes", err) } // 将插件注册到 Caddy,让 Caddy 启动时能够同时启动该插件 k.RegisterKubeCache(c) // 注册插件到调用链 dnsserver.GetConfig(c).AddPlugin(func(next plugin.Handler) plugin.Handler { k.Next = next return k }) return nil}
// coredns/plugin/kubernetes/controller.go#408// 这三个方法就是 watch 资源时的回调func (dns *dnsControl) Add(obj interface{}) { dns.detectChanges(nil, obj) }func (dns *dnsControl) Delete(obj interface{}) { dns.detectChanges(obj, nil) }func (dns *dnsControl) Update(oldObj, newObj interface{}) { dns.detectChanges(oldObj, newObj) }// detectChanges detects changes in objects, and updates the modified timestampfunc (dns *dnsControl) detectChanges(oldObj, newObj interface{}) { // 判断新老对象的版本 if newObj != nil && oldObj != nil && (oldObj.(meta.Object).GetResourceVersion() == newObj.(meta.Object).GetResourceVersion()) { return } obj := newObj if obj == nil { obj = oldObj } switch ob := obj.(type) { case *object.Service: dns.updateModifed() case *object.Endpoints: if newObj == nil || oldObj == nil { dns.updateModifed() return } p := oldObj.(*object.Endpoints) // endpoint updates can come frequently, make sure it's a change we care about if endpointsEquivalent(p, ob) { return } dns.updateModifed() case *object.Pod: dns.updateModifed() default: log.Warningf("Updates for %T not supported.", ob) }}func (dns *dnsControl) Modified() int64 { unix := atomic.LoadInt64(&dns.modified) return unix}// updateModified set dns.modified to the current time.func (dns *dnsControl) updateModifed() { unix := time.Now().Unix() atomic.StoreInt64(&dns.modified, unix)}
上面展示的就是 kubernetes 这个 Plugin Watch 各个资源变化后的回调。可以看到它仅仅只改变 dns.modified 一个值,那么当 Service 发生变化后,kubernetes 插件如何感知,并将它们更新到内存呢。其实并没有或者说并不需要。。。因为这里使用了 client-go 中的 informer 机制,kubernetes 在解析 Service DNS 时会根据直接列出所有 Service(这里其实这么说并不准确,如果查找的是泛域名,那么才会列出所有 Service,如果是正常的 servicename.namespace,那么插件会使用 client-go 的 Indexer 机制,根据索引查找符合的 ServiceList),再进行匹配,直到找到匹配的 Service 再根据它的不同类型,决定返回结果。如果是 ClusterIP 类型,则返回 svc 的 ClusterIP,如果是 Headless 类型,则返回它所有的 Endpoint 的IP,如果是 ExternalName 类型,且 external_name 的值为 CNAME 类型,则返回 external_name 的值。整个操作仍然是在内存中进行的,效率并不会很低。
// findServices returns the services matching r from the cache.func (k *Kubernetes) findServices(r recordRequest, zone string) (services []msg.Service, err error) { // 如果 namespace 为 * 或者 为 any,或者该 namespace 在配置文件中没有被 namespace: 这个配置项中配置 // 则返回 NXDOMAIN if !wildcard(r.namespace) && !k.namespaceExposed(r.namespace) { return nil, errNoItems } // 如果 lookup 的 service 为空 if r.service == "" { // 如果 namepace 存在 或者 namespace 是通配符就返回空的 Service 列表 if k.namespaceExposed(r.namespace) || wildcard(r.namespace) { // NODATA return nil, nil } // 否则返回 NXDOMAIN return nil, errNoItems } err = errNoItems if wildcard(r.service) && !wildcard(r.namespace) { // If namespace exists, err should be nil, so that we return NODATA instead of NXDOMAIN if k.namespaceExposed(r.namespace) { err = nil } } var ( endpointsListFunc func() []*object.Endpoints endpointsList []*object.Endpoints serviceList []*object.Service ) if wildcard(r.service) || wildcard(r.namespace) { // 如果 service 或者 namespace 为 * 或者 any,列出当前所有的 Service serviceList = k.APIConn.ServiceList() endpointsListFunc = func() []*object.Endpoints { return k.APIConn.EndpointsList() } } else { // 根据 service.namespace 获取 index idx := object.ServiceKey(r.service, r.namespace) // 通过 client-go 的 indexer 返回 serviceList serviceList = k.APIConn.SvcIndex(idx) endpointsListFunc = func() []*object.Endpoints { return k.APIConn.EpIndex(idx) } } // 将 zone 转化为 etcd key 的格式 // /c/local/cluster zonePath := msg.Path(zone, coredns) for _, svc := range serviceList { if !(match(r.namespace, svc.Namespace) && match(r.service, svc.Name)) { continue } // If request namespace is a wildcard, filter results against Corefile namespace list. // (Namespaces without a wildcard were filtered before the call to this function.) if wildcard(r.namespace) && !k.namespaceExposed(svc.Namespace) { continue } // 如果查找的 Service 没有 Endpoint,就返回 NXDOMAIN,除非这个 Service 是 Headless Service 或者 External name if k.opts.ignoreEmptyService && svc.ClusterIP != api.ClusterIPNone && svc.Type != api.ServiceTypeExternalName { // serve NXDOMAIN if no endpoint is able to answer podsCount := 0 for _, ep := range endpointsListFunc() { for _, eps := range ep.Subsets { podsCount = podsCount + len(eps.Addresses) } } // No Endpoints if podsCount == 0 { continue } } // lookup 的 Service 是 headless Service 或者是使用 Endpoint lookup if svc.ClusterIP == api.ClusterIPNone || r.endpoint != "" { if endpointsList == nil { endpointsList = endpointsListFunc() } for _, ep := range endpointsList { if ep.Name != svc.Name || ep.Namespace != svc.Namespace { continue } for _, eps := range ep.Subsets { for _, addr := range eps.Addresses { // See comments in parse.go parseRequest about the endpoint handling. if r.endpoint != "" { if !match(r.endpoint, endpointHostname(addr, k.endpointNameMode)) { continue } } for _, p := range eps.Ports { if !(match(r.port, p.Name) && match(r.protocol, string(p.Protocol))) { continue } s := msg.Service{Host: addr.IP, Port: int(p.Port), TTL: k.ttl} s.Key = strings.Join([]string{zonePath, Svc, svc.Namespace, svc.Name, endpointHostname(addr, k.endpointNameMode)}, "/") err = nil // 遍历 Endpoints 并将结果添加到返回列表 services = append(services, s) } } } } continue } // External service // 如果 svc 是 External Service if svc.Type == api.ServiceTypeExternalName { s := msg.Service{Key: strings.Join([]string{zonePath, Svc, svc.Namespace, svc.Name}, "/"), Host: svc.ExternalName, TTL: k.ttl} // 只有当 External Name 是 CNAME 时,才会添加该 Service 到结果 if t, _ := s.HostType(); t == dns.TypeCNAME { s.Key = strings.Join([]string{zonePath, Svc, svc.Namespace, svc.Name}, "/") services = append(services, s) err = nil } continue } // ClusterIP service // 正常情况,返回的 msg.Service 的 Host 为 ClusterIP for _, p := range svc.Ports { if !(match(r.port, p.Name) && match(r.protocol, string(p.Protocol))) { continue } err = nil s := msg.Service{Host: svc.ClusterIP, Port: int(p.Port), TTL: k.ttl} s.Key = strings.Join([]string{zonePath, Svc, svc.Namespace, svc.Name}, "/") services = append(services, s) } } return services, err}
coredns的优缺点
优点
- 非常灵活的配置,可以根据不同的需求给不同的域名配置不同的插件
- k8s 1.9 版本后的默认的 dns 解析
缺点
- 缓存的效率不如 dnsmasq,对集群内部域名解析的速度不如 kube-dns (10% 左右)
性能对比
在 CoreDNS 的官网中已有详细的性能测试报告,地址
- 对于内部域名解析 KubeDNS 要优于 CoreDNS 大约 10%,可能是因为 dnsmasq 对于缓存的优化会比 CoreDNS 要好
- 对于外部域名 CoreDNS 要比 KubeDNS 好 3 倍。但这个值大家看看就好,因为 kube-dns 不会缓存 Negative cache。但即使 kubeDNS 使用了 Negative cache,表现仍然也差不多
- CoreDNS 的内存占用情况会优于 KubeDNS
]]>