On June 9, 2026, Anthropic shipped two new models: Claude Fable 5 and Claude Mythos 5. This is not a routine version bump. For the first time, a whole new capability tier (the Mythos tier) is open to the public.
If you've been living in the Opus / Sonnet / Haiku world, here's the short version: the top-end model that used to be reserved for a handful of military-grade partners now has a "civilian edition." That's Fable 5.

I read the announcement a couple of times. Here's my summary: what these models are, how they relate, and the part I actually care about, which is when to reach for which.
The model lineup
Start with a map. Claude's models now sit in four tiers, lightest to heaviest:
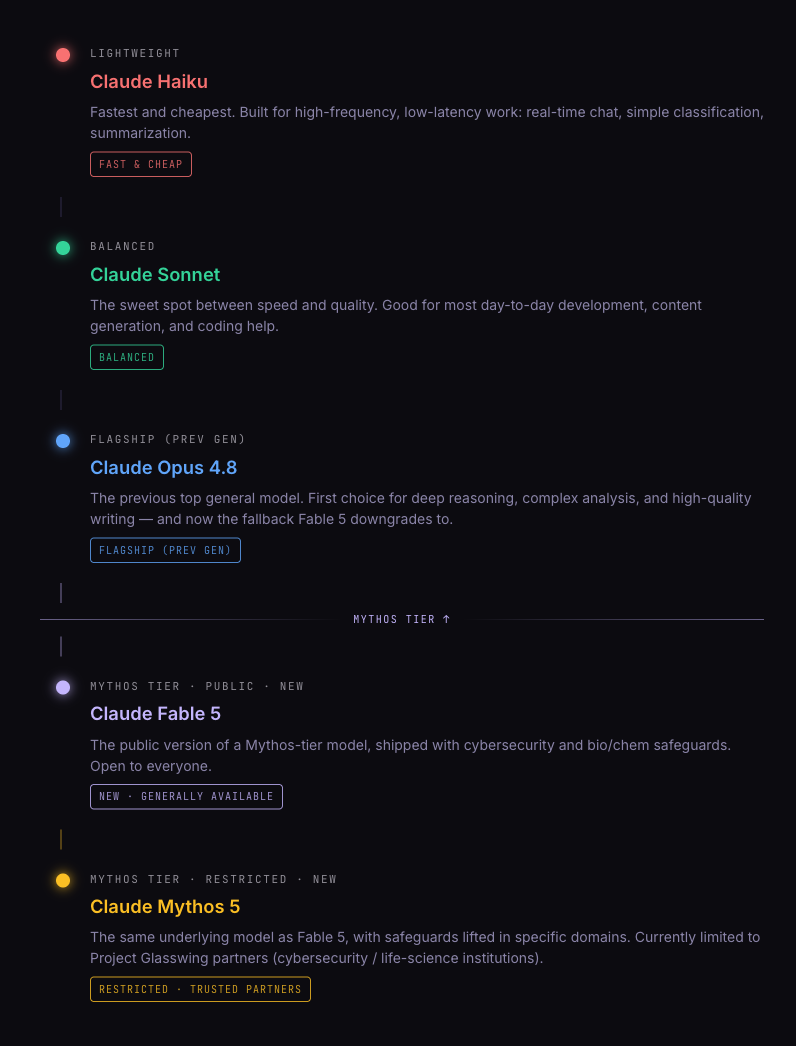
- Haiku is the fastest and cheapest. Real-time chat, classification, that kind of high-volume work.
- Sonnet is the balanced workhorse, fine for most day-to-day dev and content tasks.
- Opus 4.8 was last generation's flagship, and it's still my go-to for deep reasoning and serious writing. It picked up a second job too: it's what Fable 5 drops back to when a safeguard trips (more on that below).
- Fable 5 is the new Mythos-tier model. Public edition, safeguards on, open to anyone.
- Mythos 5 is the same underlying model with the safeguards lifted, restricted to trusted partners.
The Opus-to-Fable jump is the one to pay attention to. That's where "smarter autocomplete" turns into "an agent that can take over a multi-day task."
Fable 5: the top model, for everyone
The core pitch is simple: the longer and messier the task, the bigger its lead. Forget smoother Q&A. This thing is built to take a multi-day engineering job and run with it.
A few numbers from the release stuck with me:
- Large codebase work. In Stripe's testing, Fable 5 migrated a 50-million-line Ruby codebase in a single day. By hand, that's a couple of months for a whole team.
- Long-running agents. Inside frameworks like Claude Code it can work for days, planning phases, delegating subtasks, and checking its own output with almost no human babysitting.
- Finance-grade knowledge work. Top score on Hebbia's advanced financial-reasoning benchmark, with double-digit gains on document reasoning and chart reading.
- Vision. It rebuilt a web app's source from a single screenshot and beat Pokémon FireRed with no scaffolding. Older Claude models needed elaborate helper frameworks for that.
- Long-context memory. It stays on task across million-token jobs and can keep persistent note files to sharpen its own output.
"Fable 5 understands what users mean, not just what they type. An app that took a hundred prompts a year ago, it now nails in one." — Fabian Hedin, CTO, Replit
How the safeguards work
Here's what sets Fable 5 apart from a raw frontier model: it ships with classifiers. When a request looks like one of three sensitive categories, it quietly downgrades the response to Opus 4.8, tells you, and doesn't bill you at the Fable rate.
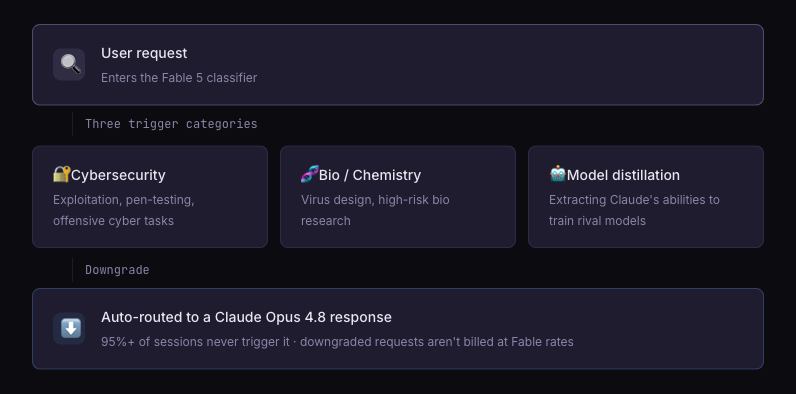
The three triggers are cybersecurity (exploits, offensive pen-testing), bio/chem (virus design, high-risk bio research), and model distillation (pulling Claude's abilities out to train a competitor). Anthropic says 95%+ of sessions never hit any of it, and when they do you land on a still-capable Opus 4.8 rather than a flat refusal.
I like this design, honestly. Instead of a hard block that kills the whole session, it just drops you a tier. For normal engineering work you'll probably never see it fire.
Mythos 5: the same model, without the rails
This is where it gets spicy. Mythos 5 is the exact same underlying model as Fable 5. The only difference is that the safeguards come off in specific domains. (The names are a wink: fable from Latin fabula, mythos from Greek. Same story in two languages, and the guardrails are the only real divider.)
What that unlocks, per Anthropic:
- Drug design. Internal protein-design experts sped up their workflow about 10x, and 9 of 14 protein targets produced strong candidates.
- Scientific hypotheses. It's the first Claude model that reliably generates novel molecular-biology hypotheses. In blind tests scientists preferred its ideas about 80% of the time, and some are already headed into the lab.
- Autonomous genomics. Over a week of autonomous work, it integrated single-cell data from 138 animal species and trained an ML model one-hundredth the size of its baseline that still beat a published Science paper.
- Cyber defense (Glasswing). The strongest cybersecurity capability around, aimed at helping defenders protect critical infrastructure. This is exactly where Fable's rails come off.
Mythos 5 is gated. For now it's available through Project Glasswing to U.S.-government-aligned cybersecurity orgs, with a trusted-access program for biomedical research institutions in the works. Anthropic says it plans to widen access over time.
It's the usual tension between capability and safety, and Anthropic's answer is guardrails plus trusted access rather than locking the capability away entirely.
Which one should you reach for?
More capable doesn't mean right for every job. Here's the comparison, dimension by dimension:

My quick heuristic:
- Sonnet for daily dev help, content generation, high-frequency API calls, anything latency-sensitive.
- Opus 4.8 for deep analysis, complex writing, a single high-quality response, or as Fable's safety net.
- Fable 5 for large codebase migrations and multi-day agent runs, the gnarly stuff where Opus hits a wall and you want the model to plan and check its own work.
One thing worth flagging: Fable 5 comes with mandatory 30-day data retention. If you're in a regulated environment, factor that in before you pipe anything sensitive through it.
Pricing
Fable 5 and Mythos 5 share the same pricing, and it's less than half of the old Mythos Preview:
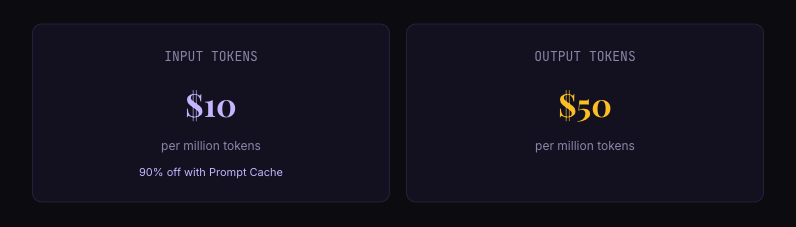
That's $10 per million input tokens and $50 per million output tokens, with cached input running about 90% cheaper through Prompt Cache. On the subscription plans (Pro / Max / Team / Enterprise), Fable 5 is free until June 22; after that it runs on usage credits until capacity catches up.
My take
What stuck with me isn't that it's stronger. It's that the thing quietly crossed from tool to collaborator. When something works on its own for days, checks its own output, and migrates a ten-million-line codebase, "smarter autocomplete" doesn't really cover it anymore.
Mythos 5 is the catch that comes attached. The more capable these things get, the more the safety question matters, and guardrails plus trusted access beats both a hard block and a free-for-all. That seems like a sane way to handle it.
For those of us building with this stuff, the question has quietly shifted from "can the AI do it?" to "are we ready for how we use it?"
Based on Anthropic's official announcement, June 2026.