在谈这个问题之前我们先来看看 drone 的结构。
结构
drone 由 3 个主要的部分组成,分别是 drone-server、drone-controller 和 drone-agent。
drone-server
顾名思义,drone-server 是 drone 的服务端,它会启动一个 http 服务来处理各种请求,如 github 每次 push 或者其他操作触发的 webhook 亦或者是 drone-web-ui 的每个请求。
drone-controller
controller 的作用是初始化 pipeline 信息,它会定义好 pipeline 的每个 step 在执行之前、执行之后以及获取和写入执行日志的函数,并保证每个 pipeline 能按顺序执行 step。
drone-agent
可以将 drone-agent 在 drone 中的作用简单的理解为是 kubelet 在 k8s 中的作用,因为本文主要讨论的是 drone 在 k8s 中的执行过程,在 k8s 中,drone 的执行并不依赖 drone-agent,所以本文并不会对该组件做详细介绍。
执行过程
server
- 当在 github 上完成一次提交后,github 会将本次提交的信息发送到
/hook,drone-server收到了请求之后,会将这些信息解析成core.Hook和core.Repository。 - 接着会根据仓库的
namespace和name在 drone 的数据库中查找该仓库,如果找不到或者项目不是 active 状态,则直接结束构建并返回错误信息。否则会将接下来的任务交给trigger来完成。
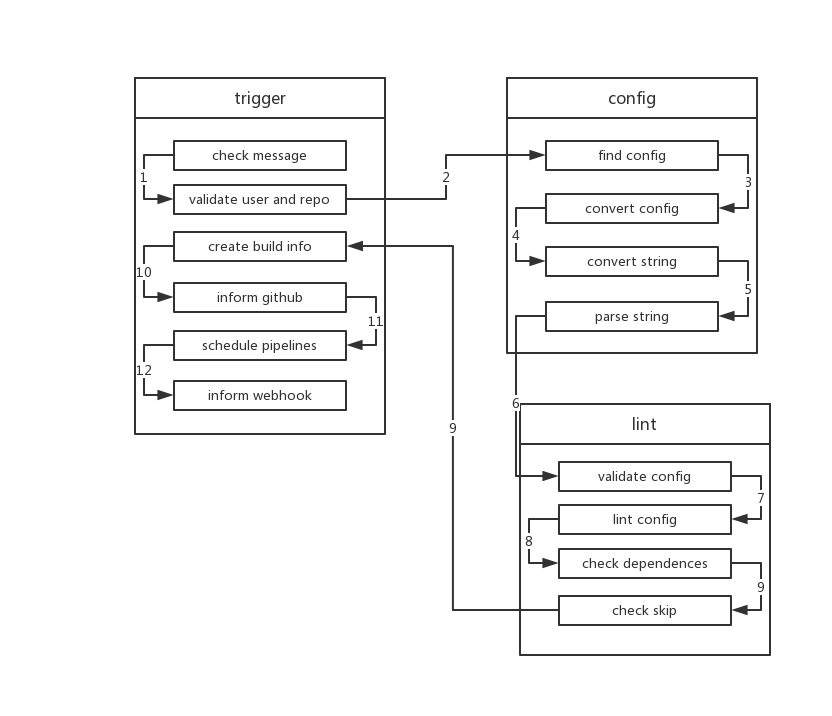
trigger
trigger接收到core.Hook和core.Repository后会检查 commit message 中是否存在[ci skip]等跳过执行 ci 的字段,如果存在则直接结束。- 接着
trigger会验证repo和owner是否合法,commit message 是否为空,如果为空trigger会调用相关 api 获取上次提交的 commit message。 - 接下来
trigger会向ConfigService请求构建的配置,一般情况下也就是.drone.yml中的内容。ConfigService可以通过DRONE_YAML_ENDPOINT这一环境变量变量扩展,如果不扩展会使用默认的FileService也就是调用 github 的相关接口来获取 file data。 - 获取到 config 后 trigger 会调用
ConvertService来转换 config,将 config 转换成yaml(因为配置文件并非都是yaml,可能是jsonnet或者script等其他格式)。ConvertService目前支持jsonnet和starlark。其中 starlark 需要使用外部扩展,也就是DRONE_CONVERT_PLUGIN_ENDPOINT来配置。 - Convert 之后,trigger 会再解析一次 yaml,这里一来是可以将旧版本的 drone 的 yaml 格式转换为新的格式,二来是 drone 兼容
gitlab-ci,这一步可以将 gitlab-ci 的配置格式转换为 drone 的配置格式。 - 接下来 trigger 将 yaml 解析成
yaml.Manifest结构体。之后会调用ValidateService来验证config、core.Build、repo owner和repo,ValidateService由DRONE_VALIDATE_PLUGIN_ENDPOINT环境变量配置,如果没有则不会这一步验证。 - 接下来
trigger会验证yaml.Manifest中每个pipeline是否合法。会检查是否有重名 pipeline,是否 step 中有自我依赖是否有依赖不存在以及权限等信息。 - 每个 pipeline 自身都通过验证后,
trigger会使用directed acyclic graph也就是有向无环图来检查各个 pipeline 之间是否有循环依赖,并检查有哪些 piepline 不满足执行条件。 - 并同时检查每个 pipeline 是否满足执行条件。包括
branch、event、action、ref等是否满足。 - 当上述验证条件都通过后,
trigger会更新数据库中的信息。然后将每个 pipeline 构建成core.Stage,stage 没有依赖,那么它的status就会被设置为Pending,这意味着它可以被执行了,如果有依赖,那么status就会被设置成Waiting。 trigger会在数据库中创建好build信息,会向 github 发送构建状态,此时在 github 中我们就能看到那个小黄点了。- 接着
trigger会遍历每个stage,并将 status 是Pending的 stage 进行调度。 - 然后将构建信息发送到环境变量
DRONE_WEBHOOK_ENDPOINT配置的地址。至此trigger的工作就结束了。
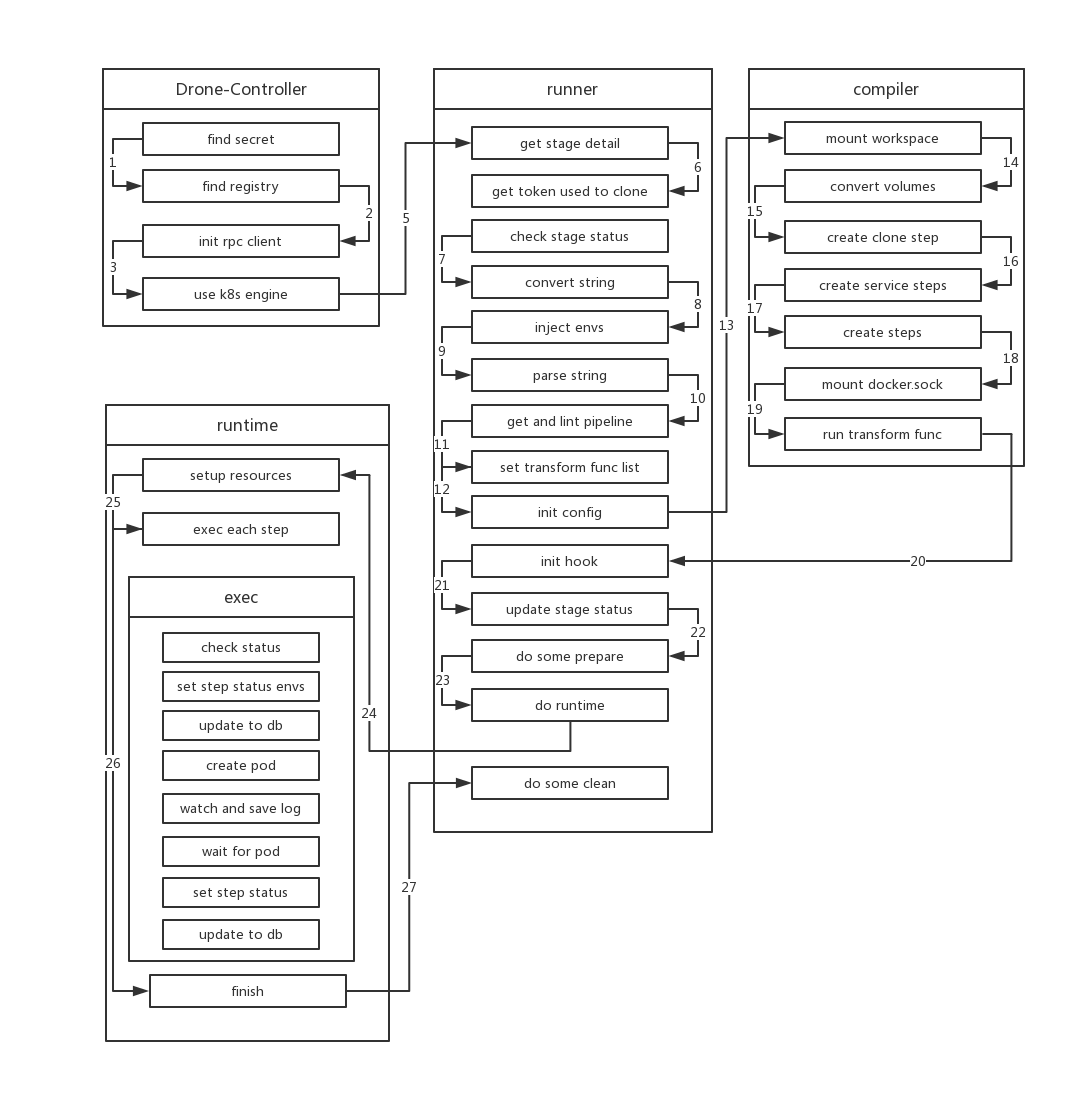
controller
因为 k8s 带来的便利性,调度 stage 仅仅需要创建一个 job,在创建 job 之前, scheduler 会将 drone-server 中的大部分环境变量注入到该 job 也就是 drone-job-stage.ID-randomString(因为 k8s 对于每个资源的名称都有规范(不能以 . _ - 开头或结尾),而在 drone 的其他 runtime 中并没有这一要求,所以为了符合 k8s 的命名规范,drone 使用了随机字符来作为资源名称。在创建 job 时,处于某些原因(后面会提到),drone 还会该 job 挂载一个 HostPath 的 volume,路径为 /tmp/drone。该 job 的 image name 就是 drone-controller。
drone-controller会初始化外部的SecretService,该 service 有DRONE_SECRET_ENDPOINT配置。- 接下来
drone-controller会初始化三个registryService,分别是 两个外部定义(由DRONE_SECRET_ENDPOINT和DRONE_REGISTRY_ENDPOINT配置) 和 本地文件(路径由DRONE_DOCKER_CONFIG定义)。 drone-controller还会初始化rpc client用于和drone-server通信。- 最后 controller 会初始化好
k8s engine,至此 controller 的初始化工作就完成了,接下来的工作会交给runner这个内部组件来执行。
runner
runner会首先根据stage的 id 向drone-server获取 stage 的详细信息。- 然后根据获取到的 repo.ID 获取 clone repo 所需要的
token。drone-server接收到该请求后会先验证 repo 和 user,通过后会向 github 获取 token,用于拉取项目。 - 然后 runner 会检查构建的状态,如果不是
killed或者skipped就会执行构建。 - 验证完成后
runner会再次解析一次yaml的格式,这一步和 trigger 中执行的步骤一样。 - 之后 runner 会将 yaml 中所有
${}内的数据替换成对应的环境变量。 - 然后 runner 会根据 stage name 来从 yaml 中获取自己需要执行的 pipeline 的详细信息(因为 yaml 中往往包含多个 pipeline),之后再对自身的 pipeline 信息进行一次 lint,这次 lint 和
trigger中第7步的操作是一样的,旨在保证元数据的合法性。 - 接着 runner 开始设置一系列的
transform function,包括registry、secret、volume等函数,这些函数会在之后的Compile中为Spec注入对应的资源,比如secret function会获取相应的 secret 并添加到spec中。 - 当上述操作都完成后,runner 便调用
compiler模块开始编译pipeline。
compiler
- 在
Compile开始时,compiler 会先确认 pipeline 的所有 steps 是否是serial的(如果 step 中存在依赖,则不是 serial)。然后会为 pipeline 挂载工作目录,也就是向spec中注入volume,该 volume 为EmptyDir。 - 接着把 yaml 中所有定义的 volumes 注入到 spec 之中。
- compiler 会检查 piepline 是否需要 clone repo,如果 pipeline 没有定义
clone:
disable: true
的话,compiler 会在 spec 中注入 clone-step,compiler 会初始化好该步骤信息,如 step name、image、mount workspace。
4. 处理完 clone step 后,compiler 会处理 pipeline 中所有的 Services,每个 Service 也会被转换成 step 注入到 spec 中,不过与普通 step 不同的是 service 会被设置为单独运行,换个说法它们不依赖任何 step,同样 compiler 会为每个 service 相关的 step 做好和 clone step 类似的初始化工作。
5. 接下来就是处理不同的 steps,处理普通 step 分两种情况,一种是 step 中使用了 build 配置,使用了这种配置 drone 会在执行该 step 的过程中自动为 repo 打包,因为打包过程中需要使用到 docker,所有在处理该 step 时,需要额外将docker.sock 文件挂在到 container,另一种情况则是按正常的流程处理。
正常的处理流程(包括clone,services 和 steps):1. 将 yaml 中的数据能复制的都复制到 spec 2. 为 spec 注入 yaml 中配置的 volumes 3. 为 spec 注入 yaml 中配置的 envs 4. 将 yaml 中的 setting 中的配置作为环境变量 “PLUGIN_:"+key: value 注入 spec (有些 env 和 setting 的值可能为 from_secret,这里就为会 spec 注入 secret)5. 将 yaml 中定义的 command 转换为 file,路径为 “/usr/drone/bin/init” 并注入 spec(之后运行时只需要运行该脚本即可)
- 最后 compiler 会执行之前定义好的所有 transform function,为 spec 注入
docker auth、来自 controller 和DRONE_RUNNER_*定义的环境变量,网络规则和SecretService中获取的 secret 等资源。至此 spec 的所有信息已经生成完毕。
hook
- 接下来 runner 会将 stage 中所有 step 的状态设置为
Pending并保存到执行列表中,并初始化runtime.Hook,在 hook 中会定义好执行每个 step 之前之后需要执行哪些步骤。在执行每个 step 之前,会创建一个streamer用于接收 log,并在数据库中更新 step 的状态,然后将 repo 的信息通过长连接推送给绑定的客户端。每次 step 执行完之后,会更新数据库中的信息,推送事件,并将之前创建的streamer删除。hook 还定义了写入日志函数,这样会将获取到的日志写入日志库。 - 定义好 hook 后,runner 会将 stage 的状态设置为
Running。在开始 build 之前,runner 会更新 stage 的状态,并将每个 step 保存到数据库,然后更新整个 build 的信息。
runtime
runner初始化好runtime的信息后就会调用runtime.Run来执行构建,这一步才是真正开始构建。runtime 先调用先前定义好的Before函数创建好 streamer,接着 k8s 会创建出一个随机字符串为 name 的 namespace,接下来所有的 step 都会在该 namespace 完成。创建好 namespace 之后会创建构建所需的secret,接着会将每个 step 中command内的信息创建为一个configmap。- 创建完成后 runtime 会开始执行每个 step,runtime 会判断各个 step 之间是否有依赖关系,如果没有则会按顺序一个一个执行。如果有依赖关系,则先运行没有依赖的 step,每次运行完该 step 后,将该 step 从其他依赖它的 step 的 depend 列表中移除,再进行如上操作,直到所有 step 都被运行(这一过程是并发的)。
- 每个 step 的执行其实就是在 k8s 中创建一个 pod,该 pod 的 image 就是设置的 yaml 中每个 step 定义的 image,所有的 pod 都会在👆的 namespace 下运行,为了保证每个 pod 都能共享文件,所有的 pod 都需要被调度到同一台机器,并且挂载同一个目录下的
HostPath Volume,而这台机器也就是drone-job-stage.ID-randomString被调度到的那台机器。当每个 pod 运行后,runtime 会注册一个回调函数来监听 pod 的变化,如果 pod 的状态变为running或者succeed或者failed之后,runtime 就会去获取该 pod 的日志,并把日志写入streamer中。最后 pod 运行结束后,runtime 会收集 pod 的退出状态,以判断是正常退出还是非正常退出。 - 等到所有的 pod 都执行完毕(或者有 pod 执行失败),runtime 首先会更新数据库中相关数据的状态,然后会做清理工作,并检查当前 build 内所有的 pipeline,如果有 pipeline 依赖其他 pipeline 并且其他 piepline 已经执行完成,那么就会
调度该 pipeline。 - 直到 build 中所有 pipeline 都完成了调度,本次 build 即为结束。